
致謝:科技部LEAP計畫 & IBM Almaden Research (Host: Howard Ho)
System-T是嵌入在提供海量數據分析解決方案的軟件IBM InfoSphere BigInsights和IBM InfoSphere Streams中的自然語言處理引擎。 System-T可以從自然語言的文本中抽取出與特定的詞類及特定的模式相符合的語句。通過該功能,軟件用戶可以在Streams中對文本數據進行實時分析,在BigInsights中對包含在大量的存儲數據中的文本數據進行分析。
System-T是嵌入在提供海量數據分析解決方案的軟件IBM InfoSphere BigInsights和IBM InfoSphere Streams中的自然語言處理引擎。 System-T能夠對文本數據中的自然語言(英語、日語、中文等)進行語言解析,抽取出特定的詞類或模式。如下例:
- 符合特定的模式的內容
- 郵政編碼
- XX市XX區等地名
- XX有限公司等公司名稱
- 郵政編碼
- 特定的詞類
- 僅抽取動詞
- 僅抽取名詞
System-T提供了AQL語言(Annotation Query Language)(註釋查詢語言,譯者譯),該語言用於指令“想要抽取的語句內容”。 AQL語言類似於SQL語言,使用create view、extract、select、output等語句進行編寫。
System-T 導覽
環境準備是要花點時間略讀一下 Installing Streams Quick Start Edition VM Image http://ibmstreams.github.io/streamsx.documentation//docs/4.2/qse-install-vm/ ,
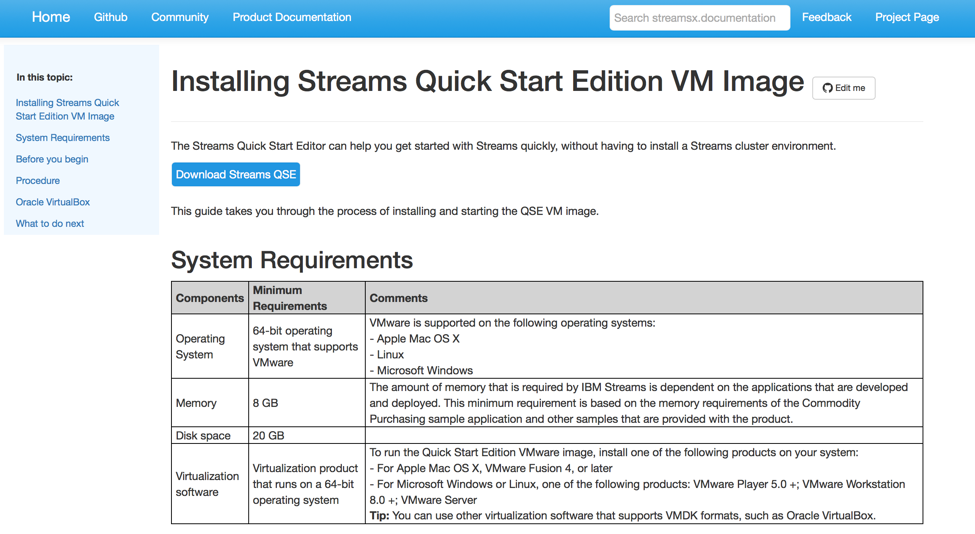
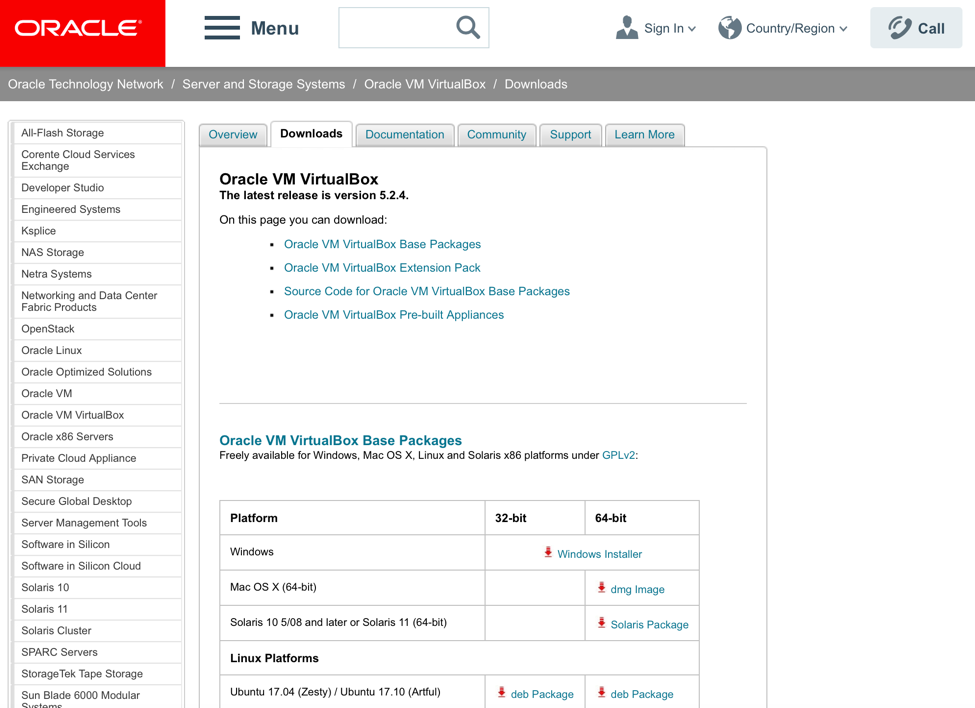
請先在機器上安裝好Oracle VirtualBox 並下載IBM Streams V4.2.1 qse 的檔案.
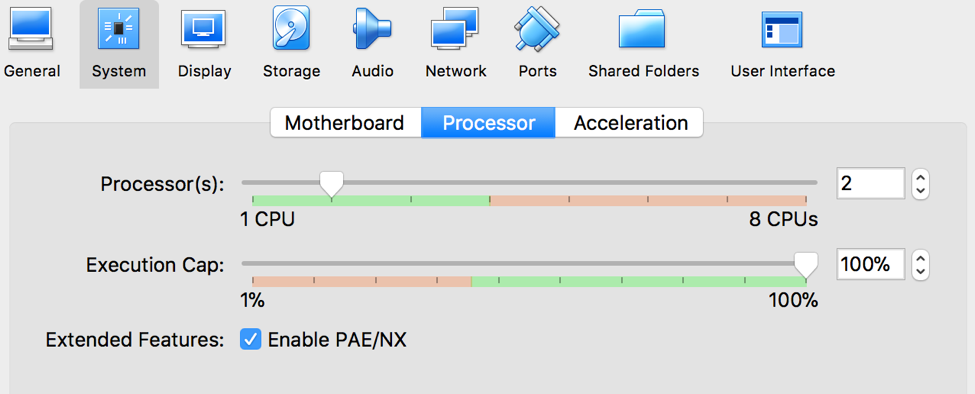
啟動 Linux (Red Hat 64 bit, 建議設定雙CPU)

開啟已經做好的vm檔的啟動畫面
如果沒有接上網路, 在 time server 這段會等很久, 並Fail, 不過沒關係對於操作沒有任何的影響
要用Tab,箭頭,Enter等按鍵來做License確認, 一直點選 [understand], 最後按 [I accept]
開始啟動image檔, 並開啟 Linux 操作桌面
下載 com.ibm.BigInsights 4.1.2.21.zip
使用內建的Eclipse 並安裝BigInsights 套件
Help > Install New Software ...

按 [Add]
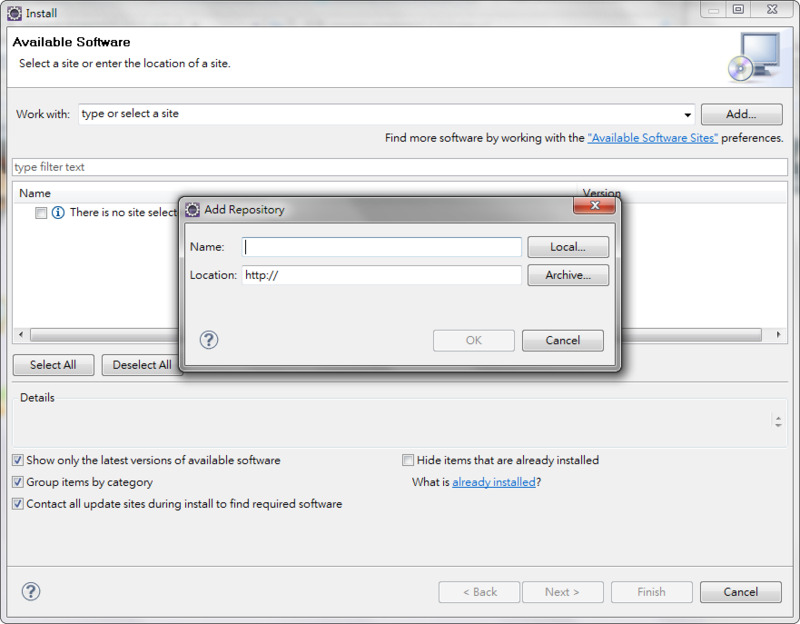
按 [Archive ...], 選擇 [BigInsightsEclipseTools.zip], 並輸入 [Name]
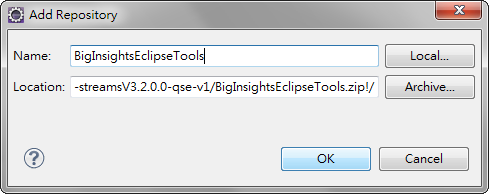
勾選 [IBM InfoSphere BigInsights]

按 [Next]

點選 [I accept...]

安裝中

忽視未安全簽證的警告, 按 [Ok], 最後重啟就安裝完成了.

系統環境設定
勾選 Window > Preferences > BigInsights > Text Analytics
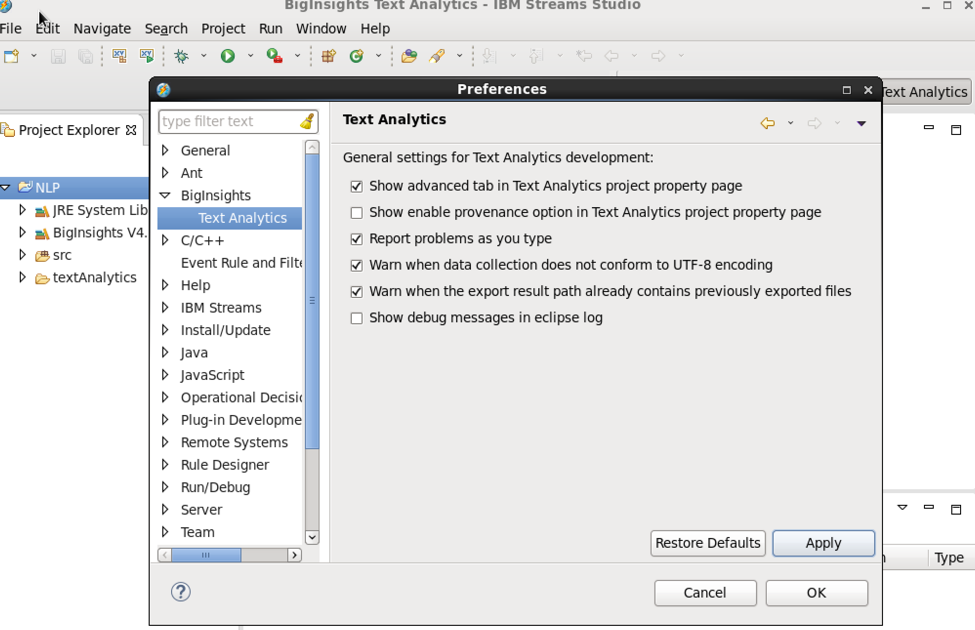
勾選 Project > Properties > BigInsights > Text Analytics > Advanced
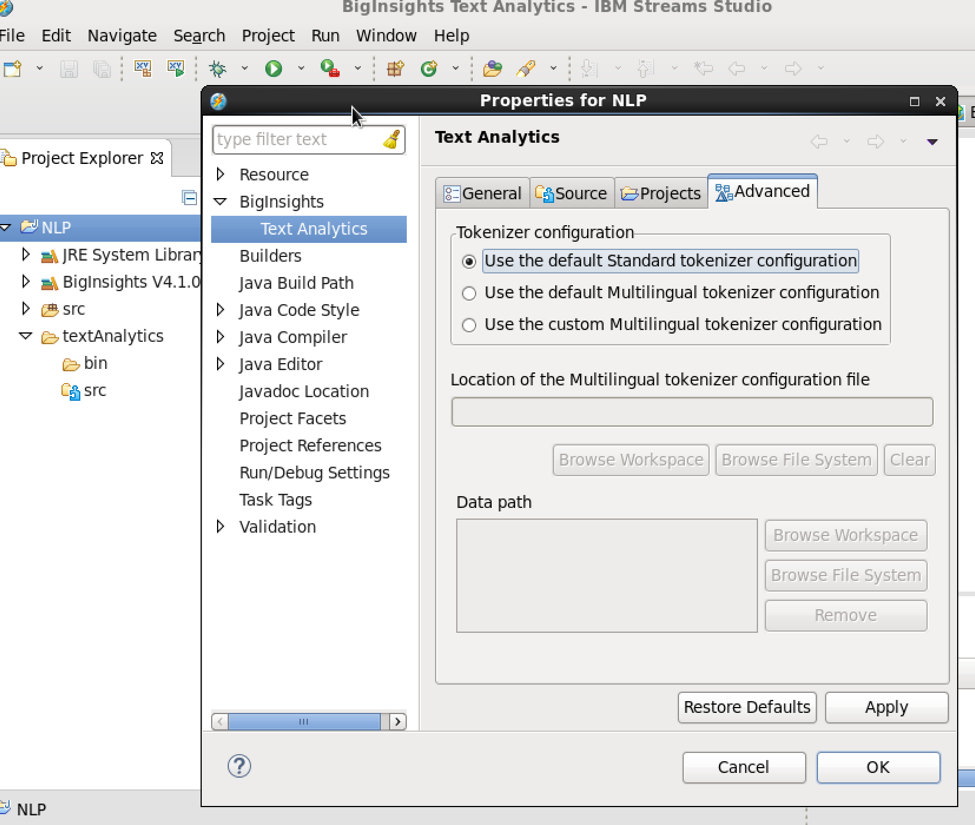
資料參考:http://hectorlee369-blog.logdown.com/posts/164781-start-the-sreams-vm
建立專案檔
使用 [Task Launcher for Big Data] > [Overview]>[First Steps], 點 [Create a new BigInsights project]
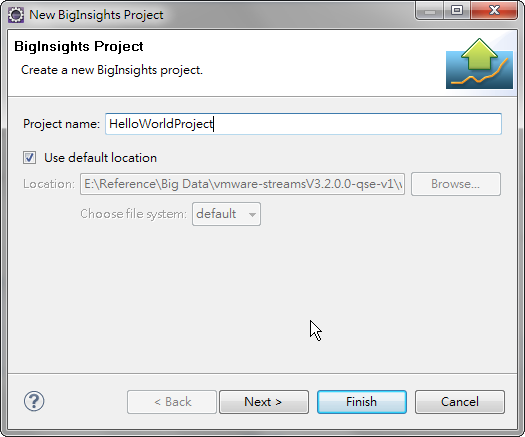
輸入專案名稱, 點 [Finish]
建立 AQL 模組
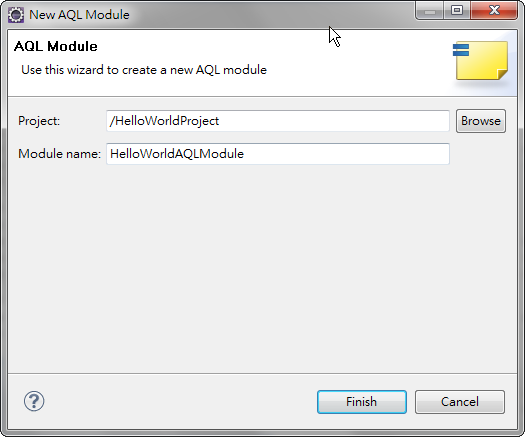
[Project Explorer] > [New] > [AQL Module]

輸入 [Module Name], 按 [Finish]
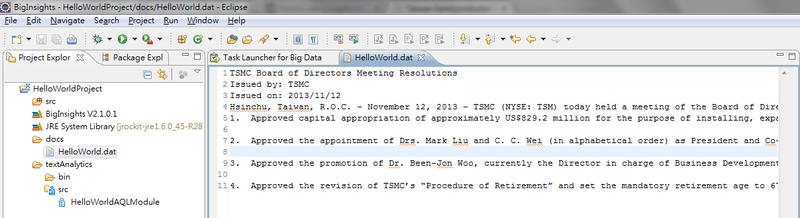
準備資料
建立一個資料夾 [docs] 做為文字解析的來源檔位置, 並建立資料檔 [HelloWorld.dat], 將公告資訊貼入及儲存
建立字典
先於 AQL Module 內建立一個資料夾 [dictionary] , 放置字典
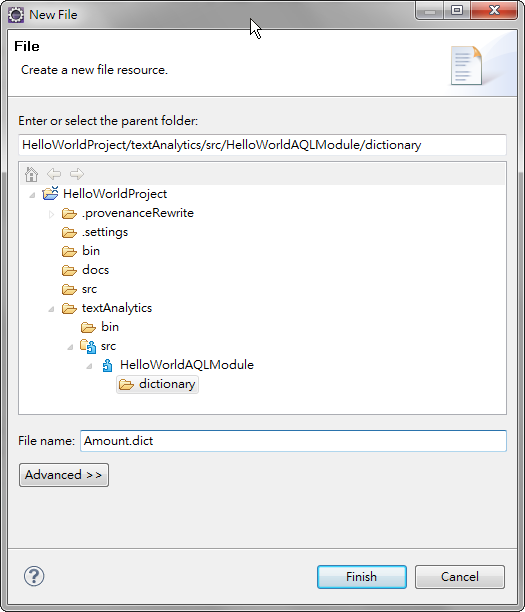
輸入我們有興趣的文字, 如: ntd, usd, $, dollar ... 等
建立 AQL Script
於 AQL Module 內建立一個 [AQL Script] , 內容如下
module HelloWorldAQLModule;
-- TODO: Add AQL content here
-- 宣告一本字典
create dictionary AmountDict
from file 'dictionary/Amount.dict'
with language as 'en';
create view AmountWords as
extract dictionary AmountDict
on R.text as match
from Document R;
output view AmountWords;
執行 Extraction Plan
切換至 [BigInsights Text Analytic Workflow]視界
在Eclipse工具列中執行Run

完成文字提取, 共有2句被找到.

建立AQL模組
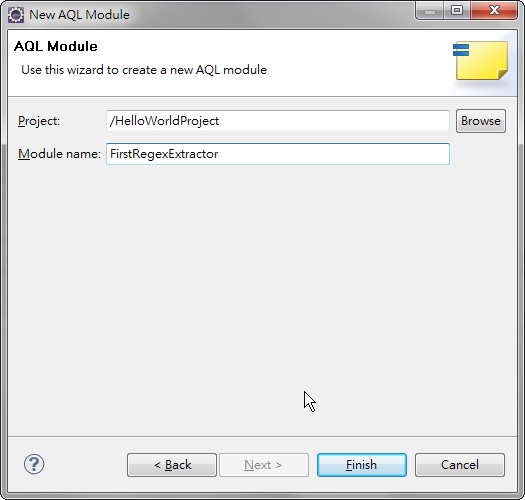
建立AQL Script
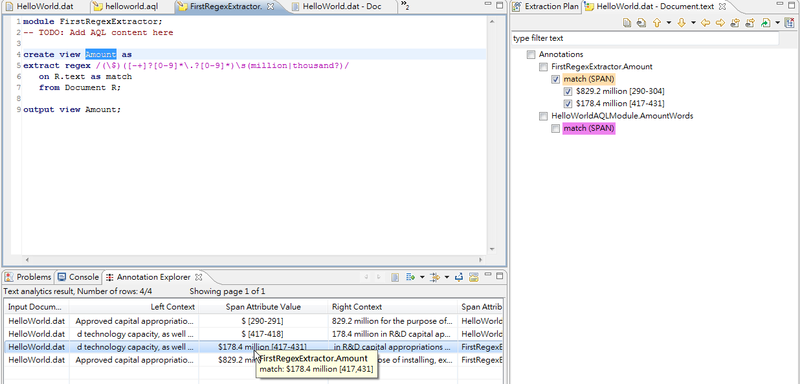
先將Script的流程架構先擬好.
module FirstRegexExtractor;
create view Amount as
extract regex //
on R.text as match
from Document R;
output view Amount;
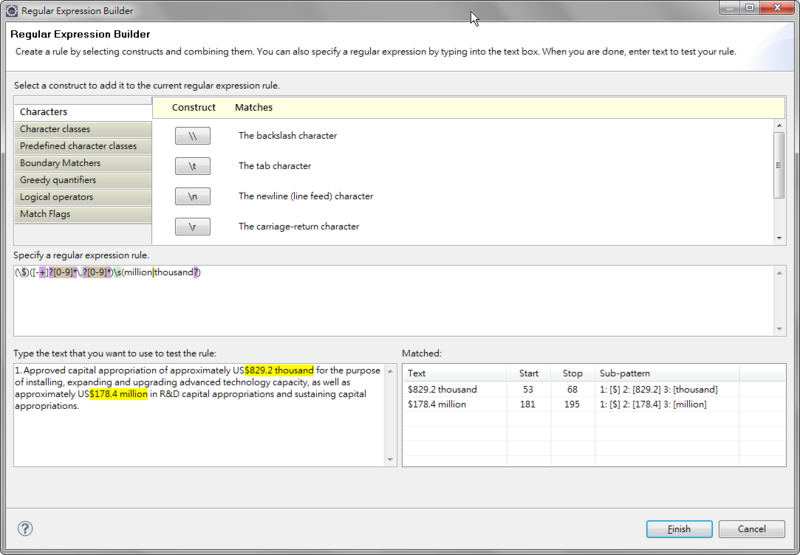
利用Regex Expression Builder, 在Script內文中的[//]處, 按下滑鼠右鍵

在[REB]工具中可輸入正規表示式的語法及範例內文,並進行測試,如範例中以取得金額的語法。
執行的結果
學習 AQL語法
--========================練習Regex, /xxxx|yyyy|zzzz/, 用|做區隔
create view dic1 as
extract regex /leasing|contract/
on D.text
return group 0 as dic1output
from Document D;
create view dic2 as
extract regex /car|van/
on D.text
return group 0 as dic2output
from Document D;
--================================練習pattern + Token 空幾個字
--================================from上述的view dic1 & dic2
create view Loc1 as
extract pattern (<B.dic2output>)<Token>{0,3}(<A.dic1output>)
return group 0 as Loc1
and group 1 as auto
and group 2 as verb
from dic1 A, dic2 B;
--===================練習Regex抓兩位數字,再抓Token跟Literal 使用 'xxx'
create view num as
extract regex /\d{2}/
on R.text as numout
from Document R;
create view Loc3 as
extract pattern (<N.numout>)<Token>{0,2}('month')
return group 0 as Loc3
and group 1 as num
and group 2 as month
from num N;
下述31~34語法 抓數字\d+後面有任何小寫英文單字[a-z]*
EX:150mm
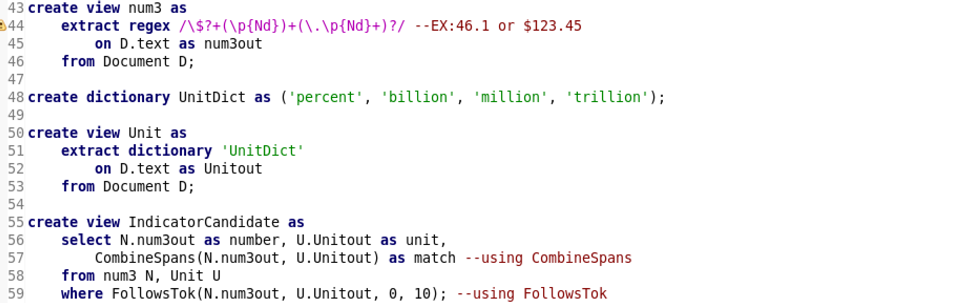
下述38~41語法 抓錢符號 EX:$123.45 billion
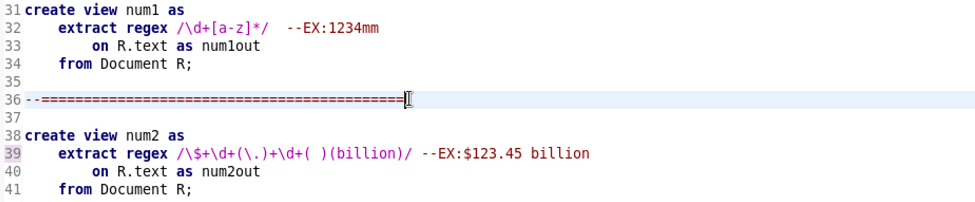
下述43~46語法 使用\$? 表示可以有$符號或沒有都抓
下述55~59語法 使用CombineSpans,使用FollosTok (前者, 後者, 中間可以多少tokens)
下述74~77語法 抓以大寫為首的字
下述81~86語法 抓連續兩個以大寫為首的字詞,中間可以空0~5個tokens

上述語法範例結果如下:
建立AQL案例
資料參考:http://www.aspphp.online/bianchen/cyuyan/cjj/cjjrm/201701/201753.html
以下為處理的文本內容:
上述的輸出結果為:Carter from Plains, Georgia, Washington from Westmoreland, Virginia
1 create view Cap as 2 extract regex /[A-Z][a-z]*/ 3 on D.text as Cap 4 from Document D; 5 6 create view Stt as 7 extract regex /Washington|Georgia|Virginia/ 8 on D.text 9 return group 0 as Stt 10 from Document D; 11 12 create view Loc as 13 extract pattern (<C.Cap>) /,/ (<S.Stt>) 14 return group 0 as Loc 15 and group 1 as Cap 16 and group 2 as Stt 17 from Cap C, Stt S; 18 19 create view Per as 20 extract regex /[A-Z][a-z]*/ 21 on D.text 22 return group 0 as Per 23 from Document D; 24 25 create view PerLoc as 26 extract pattern (<P.Per>) <Token>{1,2} (<L.Loc>) 27 return group 0 as PerLoc 28 and group 1 as Per 29 and group 2 as Loc 30 from Per P, Loc L; 31 32 create view PerLocOnly as 33 select PL.PerLoc as PerLoc 34 from PerLoc PL; 35 36 output view Cap; 37 output view Stt; 38 output view Loc; 39 output view Per; 40 output view PerLoc; 41 output view PerLocOnly;
Cap這個view提取了大寫字母開頭的英文單詞
View: Cap
+----------------------+
| Cap |
+----------------------+
| Carter:(0,6) |
| Plains:(12,18) |
| Georgia:(20,27) |
| Washington:(29,39) |
| Westmoreland:(45,57) |
| Virginia:(59,67) |
+----------------------+Stt提取了美國洲名的單詞
View: Stt +--------------------+ | Stt | +--------------------+ | Georgia:(20,27) | | Washington:(29,39) | | Virginia:(59,67) | +--------------------+
Loc對Cap和Stt進行拼接,按照中間只隔了一個逗號,且後一個單詞為州名為一個地名的規則得到地名
其中group 0指的是匹配的結果,group 1, 2 指的是匹配規則中括號的內容。
View: Loc +--------------------------------+----------------------+--------------------+ | Loc | Cap | Stt | +--------------------------------+----------------------+--------------------+ | Plains, Georgia:(12,27) | Plains:(12,18) | Georgia:(20,27) | | Georgia, Washington:(20,39) | Georgia:(20,27) | Washington:(29,39) | | Westmoreland, Virginia:(45,67) | Westmoreland:(45,57) | Virginia:(59,67) | +--------------------------------+----------------------+--------------------+
然後Per人名假設和Cap一樣
View: Per +----------------------+ | Per | +----------------------+ | Carter:(0,6) | | Plains:(12,18) | | Georgia:(20,27) | | Washington:(29,39) | | Westmoreland:(45,57) | | Virginia:(59,67) | +----------------------+
那麼PerLoc則是拼接了Per和Loc,指定中間間隔1到2個Token(以字母或者數字組成的無符號分隔的字符串,或者單純的特殊符號,不包含空白符。
View: PerLoc +------------------------------------------------+--------------------+--------------------------------+ | PerLoc | Per | Loc | +------------------------------------------------+--------------------+--------------------------------+ | Carter from Plains, Georgia:(0,27) | Carter:(0,6) | Plains, Georgia:(12,27) | | Plains, Georgia, Washington:(12,39) | Plains:(12,18) | Georgia, Washington:(20,39) | | Washington from Westmoreland, Virginia:(29,67) | Washington:(29,39) | Westmoreland, Virginia:(45,67) | +------------------------------------------------+--------------------+--------------------------------+
最後PerLocOnly則是從view PerLoc中select了一個列出來。
View: PerLocOnly +------------------------------------------------+ | PerLoc | +------------------------------------------------+ | Carter from Plains, Georgia:(0,27) | | Plains, Georgia, Washington:(12,39) | | Washington from Westmoreland, Virginia:(29,67) | +------------------------------------------------+